desktop 🠖 project information
Project Overview
Rationale
Across diverse disciplines there is increasing recognition of the important role that structural factors play in a variety of outcomes, as well the power of structural explanations to elucidate the causes of persistent inequality. However, capturing the complex network data required by these analyses remains high-burden – both for researchers and research participants.
Whereas tools for capturing and analyzing digital trace data have proliferated, there has been a clear lack of equivalent growth in methodologies such as interviewing and surveying. Even where high quality digital survey tools do exist, they are often optimized for capturing individual rather than network data.
The Network Canvas project aims to address these and other problems, by providing a set of high quality digital tools that facilitate the capture of complex network data. It provides intuitive participant facing interfaces, and powerful researcher facing tools with shallow learning curves, to enable data capture that was previously intractable.
Please see the following promotional video to learn more about our team, our objectives, and the features of the Network Canvas suite of tools.
The Components of Network Canvas
Network Canvas is organized around the stages of the research process, from design, to administration, to analysis. The desktop suite therefore consists of two different pieces of software:
- Architect - A tool for building Network Canvas interview protocols
- Interviewer - A tool for administering interviews in the field
These two applications work together to provide a seamless end-to-end workflow up to the point of analysis.
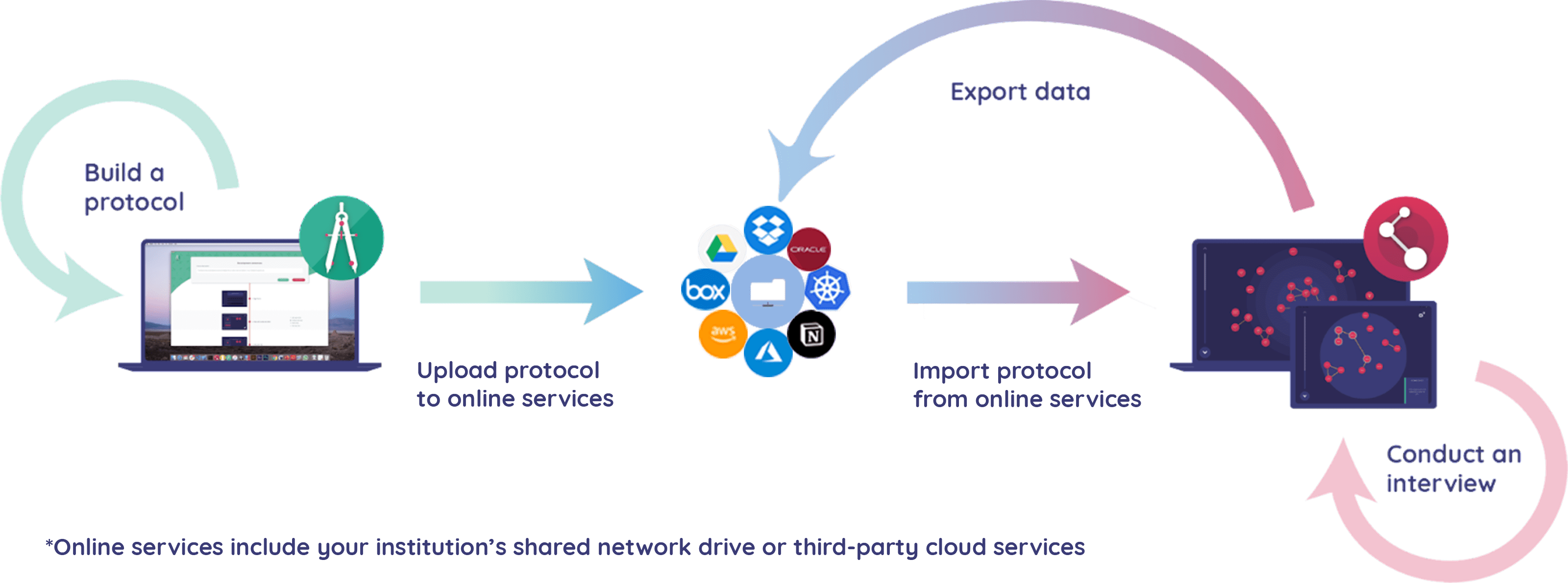
Network Canvas also includes a third piece of software, Fresco, which is a tool for deploying Network Canvas protocols built in Architect to the web.
Five Key Design Principles
Five design principles underpin each of the three pieces of software. We derived these principles from our observations and experiences regarding the problems facing researchers wishing to design and conduct personal networks research.
Ontological Flexibility
Social network analysis is not a singular methodology, but a broad approach to research which straddles multiple disciplines and research ontologies. We are aware that these perspectives often disagree on fundamental elements of the research process, which led us to focus on designing fundamental ontological flexibility into the software. This ensures that we impose the fewest possible number of constraints on the type of study that can be developed.
This flexibility begins with the core abstraction of the data model: you are free to define the nodes and edges of your interviews, along with their attributes, in whichever terms suit your framing. There is no limit on the number or type of these 'entities', or any assumption about how they relate.
Next, you define the content of your interview in its entirety. This means you control both the sequence of data collection tasks, as well as the way these tasks are defined to the participant. Thus, a great deal of flexibility is possible in terms of finessing the network object.
In-person and Interviewer-assisted
We believe that what constitutes "high quality data" is fundamentally situational and context-specific. In the case of the Network Canvas project, our research team had previously struggled specifically with the challenges of collecting highly sensitive and deeply intimate data in a research setting. This led us to value the specific advantages offered by in-person and interviewer-assisted approaches in shaping the 'theater' of the interview.
We therefore designed the Network Canvas tools on the assumption that interviews occur in the presence of an interviewer, on an interviewer-controlled machine, and with the interviewer having been specifically trained in guiding the interview process.

Of course, we recognize that it is not always possible to conduct interviews in this manner. Some users have had success with implementing Network Canvas interviews using screen sharing technology (which may be a viable workaround for those who simply cannot be in a face-to-face context).
We also recognize that workflows that involve unsupervised data collection, and/or self-administered interviews are important to network researchers. Our focus with this project is to do the best possible job of designing an interviewer-assisted and in-person experience, but we are actively exploring how future work might supplement the software suite with web-based or remote interview options.
"Visuality" and an emphasis on user experience
We put significant effort into the visual design of our software, both in terms of participant facing and researcher facing interfaces. This is not simply an aesthetic veneer, but is rather intended as a fundamentally functional 'feature' that differentiates our approach.
Issues associated with poor visual design in survey methodology have been extensively documented in the literature. Interfaces that confuse participants or bias the task lead to demonstrably lower quality data. We believe this is particularly true for networks research, because it has the added burden of asking 'unusual' questions and introducing often alien concepts and metaphors. Our approach has been to draw on Human-Computer Interaction (HCI) literature, as well as papers from the network analysis community that have advanced the design and implementation of network interviews in novel ways. We have combined this with our own ideas and improvements, to create an interview experience that is engaging and simple for participants to understand, with clear, consistent, and tactile interactions.

Design issues are not confined to participants, however. Software designed for researchers often requires that they become experts in the software itself before they can be productive. Our approach aims to allow researchers to focus on their status as subject experts, and to pick up the concepts they need to implement their ideas as they go. Architect and Fresco present interfaces that are helpful, clear, and that strike a balance between sophistication and simplicity.
End-to-end Workflow
A key element of our approach is to focus on the process of 'doing research' holistically. Our experience taught us that the obstacles to conducting networks research are not isolated within any one part of the process, but are both within the individual stages and threaded through the process as a whole.
The initial incarnation of the Network Canvas concept provided simply an interview tool, with the protocol hard coded in a text based format that required a high degree of technical knowledge from would-be research designers. Data we collected using this tool then needed to be painstakingly cleaned and managed, using using a series of scripts and processes.
We therefore decided that simplifying the process of collecting complex structural data required not just an interview tool, but also a tool for designing these interviews, as well as a tool for managing and exporting data. This complete end-to-end workflow lowers the costs (both material and technical) for network researchers.
Open-Source Development
We knew that the key to sustaining this effort would be input and collaboration with the community. We noted that 'black-box' development produces much research software (meaning that implementations cannot be improved or scrutinised) and is driven by top-down processes. We also noted that developing software and tools incurrs significant financial costs and technical costs, often placing it out the reach of the majority of researchers, and incentivising commercialisation as a means to make development practical.
We believe that in order to break out of these practices, we needed to develop a strong foundation that would enable others to build upon it, while sharing improvements and enhancements with all users. To move Network Canvas in this direction, we made the code itself completely open-source, implemented a community driven development programme, and made the software free to use.
We established a not for profit entity (the Complex Data Collective - or CODACO) which owns all IP and copyright associated with the project. CODACO licenses Network Canvas under the "GPLv3" which is a popular open source license that gives all users certain guaranteed freedoms.
- Freedom to use the software commercially, without restriction
- Freedom to modify the software however they see fit
- Freedom to distribute the software
These freedoms are protected by some requirements built into the GPL license:
- Any modifications must be made available under the GPL license
- You must include a copy of the original source code with any versions you distribute, making it possible for others to modify